Exporting RDS Snapshots to Athena using Step Functions
A secure, efficient, and hassle-free way to run data analytics queries

An architect by trade, practicing architecture in the Cloud. 7x AWS Certified, AWS Community Builder, Serverless advocate, Vue enthusiast.
A recent challenge I had on a project was enabling access to a production MySQL database on Amazon RDS, mostly for data analytics purposes. The requirement was to run ad-hoc SQL queries for periodic analytics reports and extract data to populate some non-real-time dashboards.
Allowing direct access to the production database was a flat-out "nope" for security reasons and because any direct interaction with the production database poses potential risks.
Now, you might wonder, "Why not just spin up an RDS read replica and call it a day?". Good question!
An RDS read replica could have been a straightforward choice, a sidekick that would allow our non-dev colleagues to run SQL queries without stirring up any trouble in the production setup.
But there was no need for real-time data, most of the queries are done on previous days, if not weeks or months' data, so a 24-hour data replication delay was acceptable, and keeping up an additional RDS instance would be unnecessary.
A principle that resonates with my identity as a cloud architect is to focus on crafting secure and efficient solutions and avoid unnecessary infrastructure. This often leads me towards serverless approaches.
As we have automated backups enabled on our RDS instance, it means we have daily snapshots that are already available, the only thing left is getting that data into S3 so it can be crawled with Glue and queried using Athena.
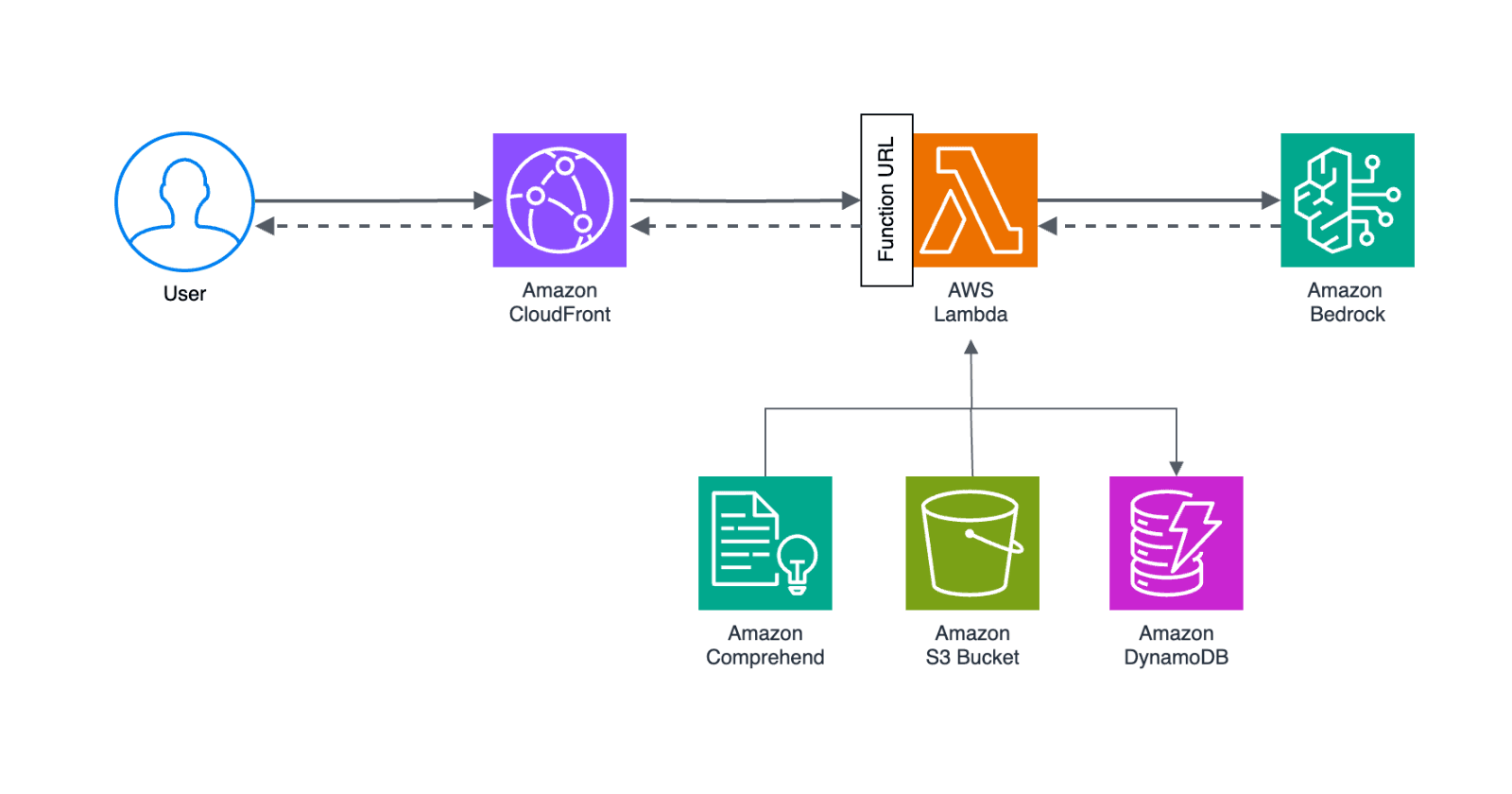
And this is the architecture I came up with:

I love working with Step Functions, it's like having superpowers to orchestrate various services while having a crystal-clear view of the workflow, and when it comes to event-driven architectures, I find it satisfying to design systems that dynamically respond to specific events or changes.
So, Step Functions and EventBridge together? I'm all in!
The service components
RDS instance - with automated backups enabled (you probably have it already)
S3 Bucket - where the RDS data gets exported to and crawled from
KMS key - to keep the things encrypted
2 Lambda functions - one to prepare the export files for crawling, the other to send SendTaskSuccess to resume workflow execution
3 EventBridge rules - listen for snapshot/export/crawler events
Glue Crawler - prepares and organizes the data catalog
Step Function - orchestrates the workflow
RDS Snapshots
The first step is to find out when an RDS automated snapshot is created, for this we create an EventBridge rule that will match the RDS DB snapshot event.
The automated snapshot names have the following format rds:dbid-yyyy-mm-dd-hh-mm
{
"detail-type": ["RDS DB Snapshot Event"],
"source": ["aws.rds"],
"detail": {
"Message": [{
"prefix": "Automated snapshot created"
}],
"SourceIdentifier": [{
"prefix": "rds:YOUR-DB-ID"
}]
}
}
When an automated snapshot gets created the event will match the above pattern, and fire up our Step Function execution.
Exporting RDS Snapshot to S3
Once the snapshot is created we need to export it into S3.
So, the first state of our Step Function is StartExportTask which will take care of the export.
"StartExportTask": {
"Type": "Task",
"Next": "Wait for Export (TT)",
"Parameters": {
"ExportTaskIdentifier.$": "States.ArrayGetItem(States.StringSplit($.detail.SourceIdentifier, ':'),1)",
"IamRoleArn": "${ExportRoleArn}",
"KmsKeyId": "${KmsKeyId}",
"S3BucketName": "${S3Bucket}",
"SourceArn.$": "$.detail.SourceArn"
},
"Resource": "arn:aws:states:::aws-sdk:rds:startExportTask"
}
The ExportTaskIdentifier is the name of the Export to S3 task and will also be the S3 folder where the data is exported. Note each Export Task name needs to be unique and for some reason, an Export to S3 task can't be deleted once created.
We use the Intrinsic Functions to remove the rds: prefix from the SourceIdentifier so we can use it as an S3 folder name.
The data will be exported in S3 in Apache Parquet format, the process is asynchronous and takes quite a bit. It depends on your database type and size, as the export task first restores and scales the entire database before extracting the data to Amazon S3.
In my experience, it takes at least 30 minutes just to get the export task out of STARTING status and a minimum of 5 minutes to COMPLETE.
Waiting for the Export to S3 to complete
Now, we need to wait for the Export to S3 to complete. As mentioned previously, the Export Task is asynchronous, it runs in the background so we need to pause our workflow and for this, we will add a state with a callback.
A state with a callback in Step Functions allows the workflow to pause until an external process signals its completion by calling the SendTaskSuccess (or SendTaskFailure) APIs with a task token.
The Wait for Export (TT) state will store the task token into an object in our S3 bucket and pause the workflow. Note the .waitForTaskToken suffix to the Resource ARN.
{
"Wait for Export (TT)": {
"Type": "Task",
"Next": "Move Exported Objects",
"Parameters": {
"Body.$": "$$.Task.Token",
"Bucket": "${S3Bucket}",
"Key": "export_task_token"
},
"Resource": "arn:aws:states:::aws-sdk:s3:putObject.waitForTaskToken",
"HeartbeatSeconds": 3600,
"ResultPath": null
}
}
To find out when the Export to S3 task gets completed we created another EventBridge rule with the following pattern:
{
"detail-type": ["RDS DB Snapshot Event"],
"source": ["aws.rds"],
"detail": {
"SourceIdentifier": [{
"prefix": "rds:YOUR-DB-ID"
}],
"Message": [{
"prefix": "Export task completed"
}]
}
}
Matching the above pattern signals the snapshot export is complete and will invoke the Lambda function that's responsible for resuming our workflow. The Lambda reads the task token that was written in the S3 object and calls SendTaskSuccess API.
const { SFNClient, SendTaskSuccessCommand } = require("@aws-sdk/client-sfn"),
{ S3Client, GetObjectCommand } = require("@aws-sdk/client-s3");
const sf = new SFNClient(), s3 = new S3Client();
exports.handler = async (event) => {
// get the task token from s3
const taskToken = await s3
.send(
new GetObjectCommand({
Bucket: process.env.S3_BUCKET,
Key: event.source === "aws.glue" ? "glue_task_token" : "export_task_token",
})
)
.then((data) => data.Body.transformToString("utf-8"))
.catch((err) => {
console.log(err);
return null;
});
// send the task token to step function
await sf.send(
new SendTaskSuccessCommand({
output: JSON.stringify(event),
taskToken: taskToken,
})
);
return;
};
Preparing the data for the Glue Crawler
Now that we have the data exported in S3 in Apache Parquet we need to move it in the folder our Glue Crawler was instructed to look for it.
Every export is made in a different folder uniquely named after the export task identifier, so we need to move the Parquet files into the data folder so it can be crawled. Here's the Lambda function that does the job:
const { S3Client, ListObjectsV2Command, CopyObjectCommand, DeleteObjectCommand } = require("@aws-sdk/client-s3");
const s3 = new S3Client();
exports.handler = async (event) => {
// list the objects in the bucket
const objects = await s3
.send(
new ListObjectsV2Command({
Bucket: process.env.S3_BUCKET,
Prefix: event.prefix,
})
)
.then((data) => data.Contents)
.catch((err) => {
console.log(err);
return null;
});
// copy the objects to the data folder
for (const object of objects) {
await s3
.send(
new CopyObjectCommand({
Bucket: process.env.S3_BUCKET,
CopySource: `${process.env.S3_BUCKET}/${object.Key}`,
Key: `data/${object.Key.split("/").slice(1).join("/")}`,
})
)
.then(() => {
// delete the old object
s3.send(
new DeleteObjectCommand({
Bucket: process.env.S3_BUCKET,
Key: object.Key,
})
);
})
.catch((err) => {
console.log(err);
return null;
});
}
};
To be honest, I didn't want to use Lambda function for this but there was no other option. I initially tried using states directly in the Step Functions, unfortunately, the string manipulation is still very limited with Intrinsic Functions, and didn't find a good way to remove the prefix from the S3 Object Key to move the exports to the standardized folder. The flow would have looked as below:
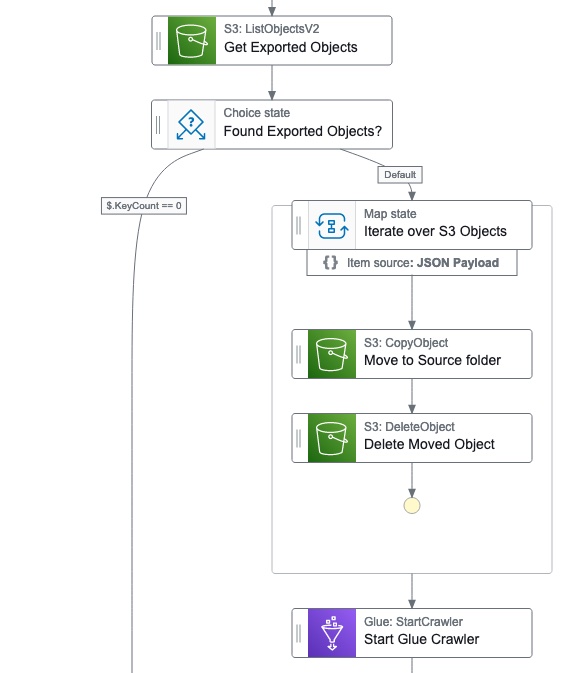
Crawling the data
Once the data is moved we can start the Glue Crawler and prepare it to be queried by Athena.
The Glue Crawler analyzes the content and structure of the data, extracting key details such as table definitions and column information. This metadata is then stored in the AWS Glue Data Catalog, allowing Athena to query the data.
The crawl process is also asynchronous and takes a couple of minutes.
Waiting for the Glue Crawler to complete
In my Step Function, I added another state that waits for the crawl to complete, this is optional. I added it because I want to be notified if the workflow fails (not part of the article/template).
It uses the same technique, writing the task token to an S3 object and pausing the workflow until an event matches the below pattern and the Lambda gets invoked to resume the process.
{
"detail-type": ["Glue Crawler State Change"],
"source": ["aws.glue"],
"detail": {
"crawlerName": ["my_crawler_name"],
"state": ["Succeeded"]
}
}
Note the Standard Workflow for Step Functions can run up to a year, and we pay per state transition, so waiting for the callback won't cost extra.
However, I set a heartbeat to 3600 seconds for both states using a callback to allow the entire workflow to timeout if the Glue Crawled doesn't complete within that timeframe.
And there you have it – a secure, cost-efficient, and hassle-free way to run SQL queries on your RDS data while keeping your production database safe.
Summary
Here's the 1-click Deployment link to get going quickly, or click to view the complete self-contained Cloudformation template that can be deployed into any AWS account.