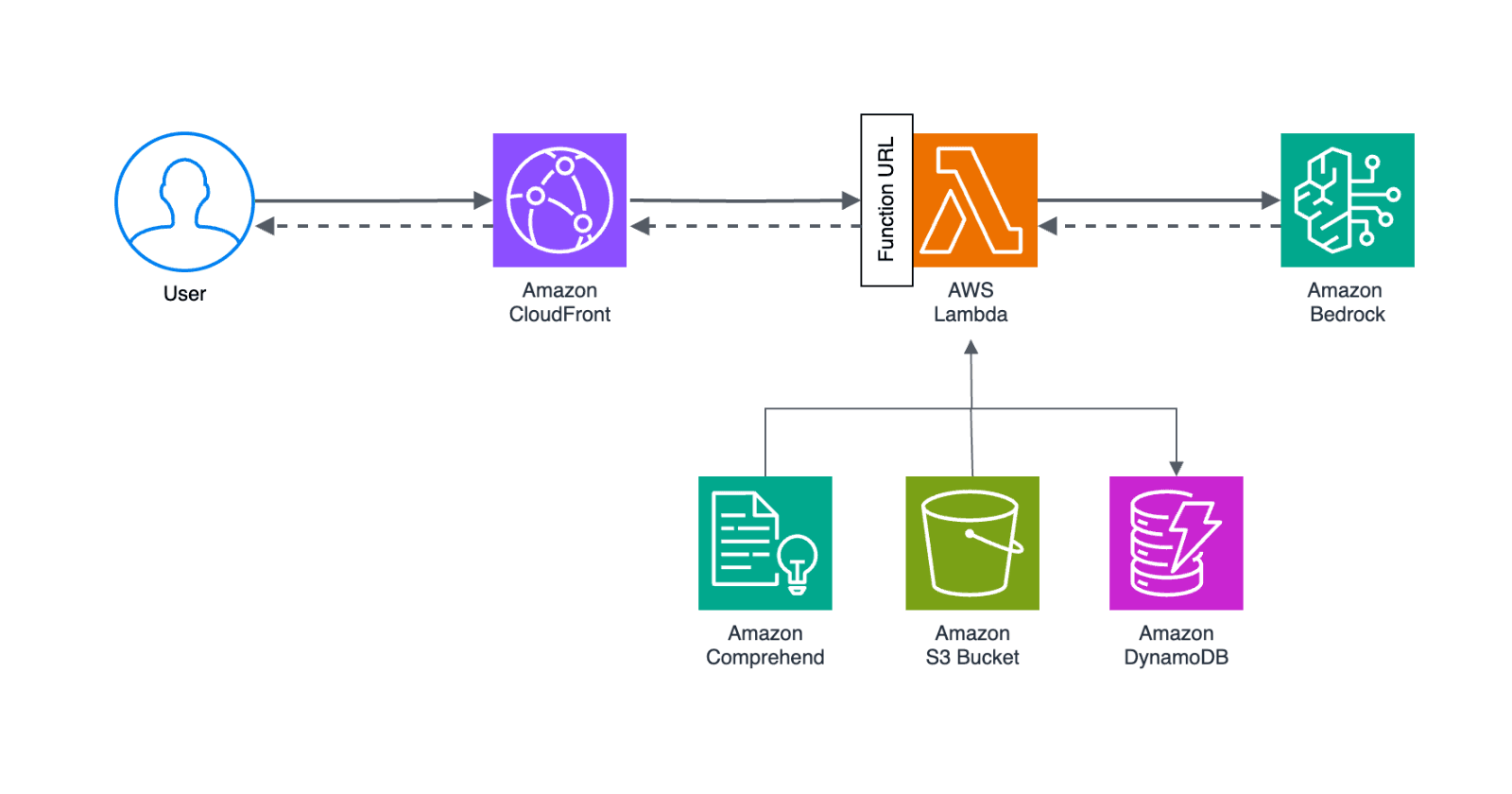
I'm building monithor.co - an open-source web monitoring service built with Serverless on top of AWS. It's using DynamoDB as the database, a highly performant NoSQL database that's been increasingly popular for serverless applications over the past years.
After more than a decade of dealing mostly with relational databases, using DynamoDB requires looking at things from a different angle, unlike traditional SQL databases, it does not use table joins and other relational database constructs. However, we can model many common relational designs in a single DynamoDB table but the process is different.
DynamoDB Table Basics
Before getting deeper into things let's summarize the DynamoDB table basic concepts:
- Partition (hash) key (PK) - defines in which partition the data is stored into
- Sort (range) key (SK) - defines the sorting of items in the partition, and it's optional. You can query it by condition expression (=, >, <, between, begins_with, contains, in) combined with PK
- Local secondary index (LSI) - allows defining a different sort key for PK. It can only be created when the table is created
- Global secondary index (GSI) - allows defining a new partition and/or sort key. GSI is the central part of most design patterns in a single table design. Both LSI and GSI are implemented as copying all the data to a new table-like structure
- Attributes - can be scalar (single value) or complex (list, maps, sets)
There are three ways of reading data from DynamoDB:
- GetItem - retrieves a single item from a table. This is the most efficient way to read a single item because it provides direct access to the physical location of the item.
- Query - retrieves all of the items that have a specific partition key. Within those items, you can apply a condition to the sort key and retrieve only a subset of the data. Query provides quick, efficient access to the partitions where the data is stored.
- Scan - retrieves all of the items in the specified table. (This operation should not be used with large tables, because it can consume large amounts of system resources.
Key concepts when using DynamoDB
Know your access patterns in advance
You shouldn't start designing the DynamoDB schema until you know the questions it will need to answer. Understanding the business problems and the application use cases upfront is essential. Write down all the access patterns, here's what the access pattern list looks like for Monithor.
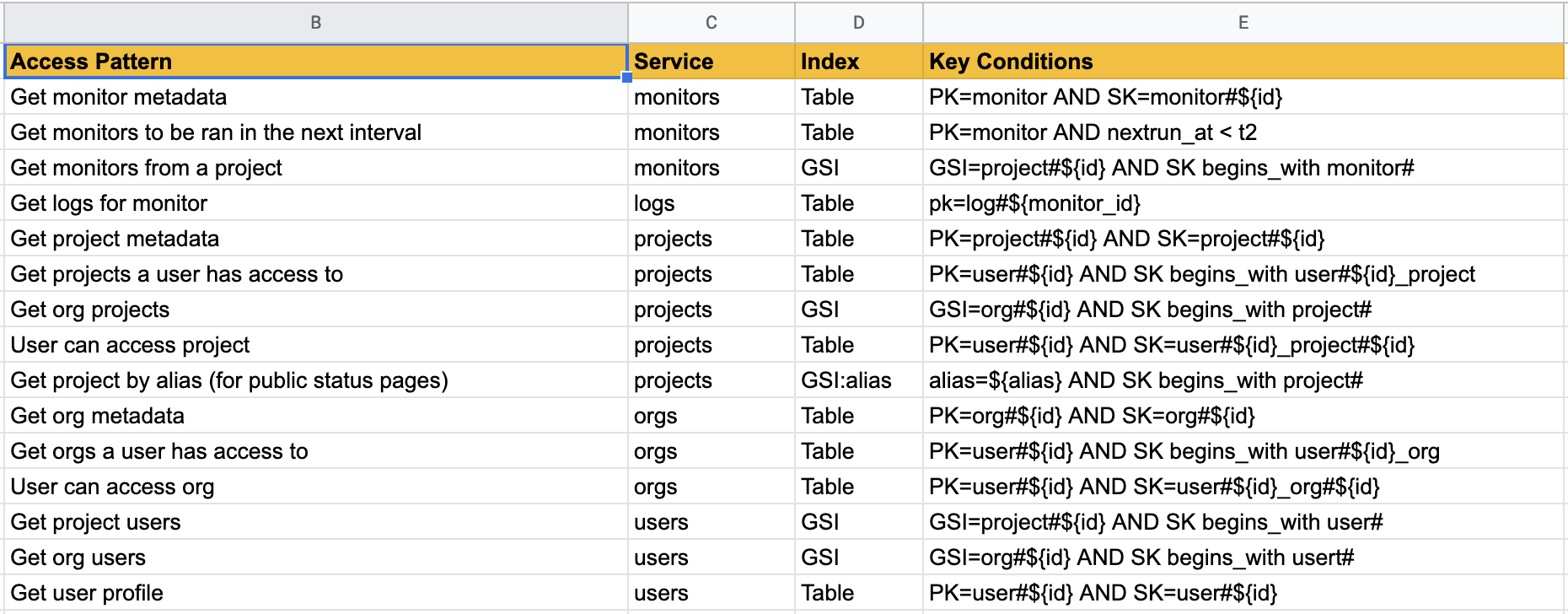
Our table can grow quite big so we want to avoid Scan at all costs so we'll create our data model so we can extract what we need using Query and GetItem.
Single table design
You should maintain as few tables as possible in a DynamoDB application, we'll go with a single table design.
Yes, having all the data in a single table might look confusing and hard to read, but it offers a rich set of flexible and efficient design patterns, better utilization of resources, and easier configuration, capacity planning, and monitoring.
When using a single table, use generic attributes for the primary key like PK (partition key), SK (sort key), GS1PK (first global secondary index partition key), GS1SK (first global secondary index sort key).
Also, identify the type of the item by prefixing keys with type. e.g. project#1234 (project = type, 1234 = id)
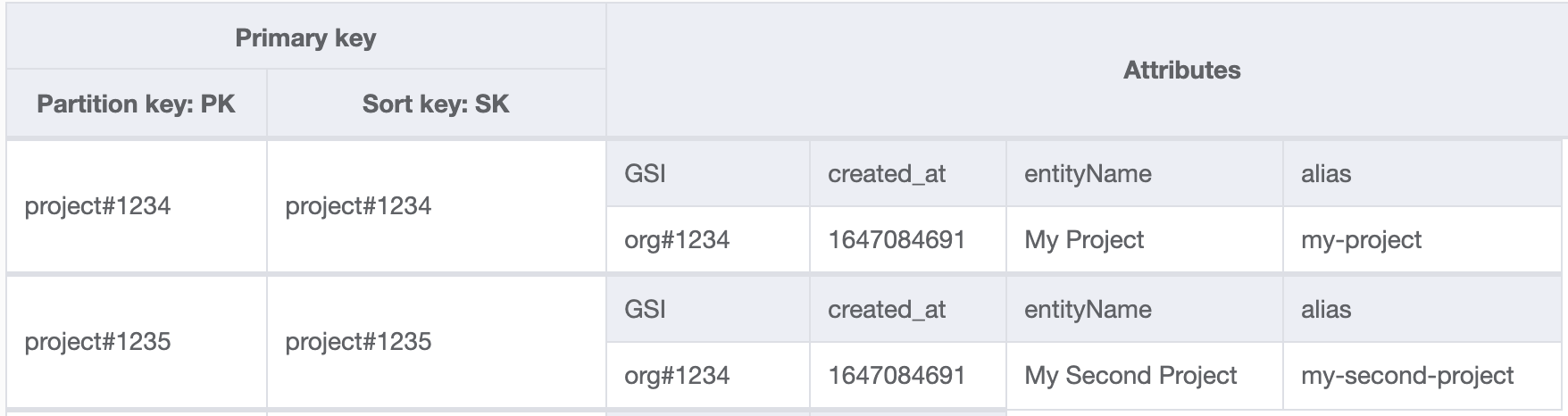
The DynamoDB single-table design requires a different mindset than relational database table design, I recommend using NoSQL workbench for DynamoDB for data modeling and visualization. https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/workbench.html
Monithor's Table Design
- a composite primary key (PK and SK)
- a local secondary index with the sort key created_at - allows querying PK created within an interval of time
- a local secondary index with the sort key nextrun_at - allows querying PK due to be executed within a time interval
- a global secondary index (GSI) with the sort key set as table's sort key (SK)
Here's the CloudFormation template for our DynamoDB single table.
Resources:
ddbTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: ${self:custom.resourceName}
AttributeDefinitions:
- AttributeName: PK
AttributeType: S
- AttributeName: SK
AttributeType: S
- AttributeName: created_at
AttributeType: N
- AttributeName: nextrun_at
AttributeType: N
KeySchema:
- AttributeName: PK
KeyType: HASH
- AttributeName: SK
KeyType: RANGE
LocalSecondaryIndexes:
- IndexName: pk_created
KeySchema:
- AttributeName: PK
KeyType: HASH
- AttributeName: created_at
KeyType: RANGE
Projection:
ProjectionType: ALL
- IndexName: pk_run
KeySchema:
- AttributeName: PK
KeyType: HASH
- AttributeName: nextrun_at
KeyType: RANGE
Projection:
ProjectionType: ALL
GlobalSecondaryIndexes:
- IndexName: GSI
KeySchema:
- AttributeName: GSI
KeyType: HASH
- AttributeName: SK
KeyType: RANGE
Projection:
ProjectionType: ALL
BillingMode: PAY_PER_REQUEST
TimeToLiveSpecification:
AttributeName: expires_at
Enabled: TRUE
Relational data
Modeling relational data in DynamoDB requires reusing or overloading keys and secondary indexes for different purposes. Overly-simplified, the data model for Monithor looks as in the diagram below.
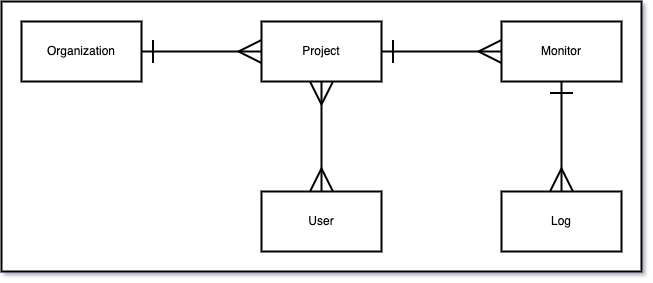
- Organization - the account that owns the projects & cloud subscription, an organization can have multiple projects (one-to-many)
- Project - the monitors are organized into projects for easier monitoring and access control, a project can have multiple monitors (one-to-many), but a project also has and belongs to many users (many-to-many)
- Monitor - the monitor will create a log entry with the result of each execution, so a monitor can have multiple logs (one-to-many)
One-to-Many relationship
Let's take aside the relationship between projects and monitors, a project can have multiple monitors. In the UI we'll have to display all the monitors of a project, so we'll have to create an API endpoint that will query all monitors by project ID.
We rely on the GSI global secondary index, for each monitor entry we'll populate the GSI with the project ID prefixed with the entity type project#.
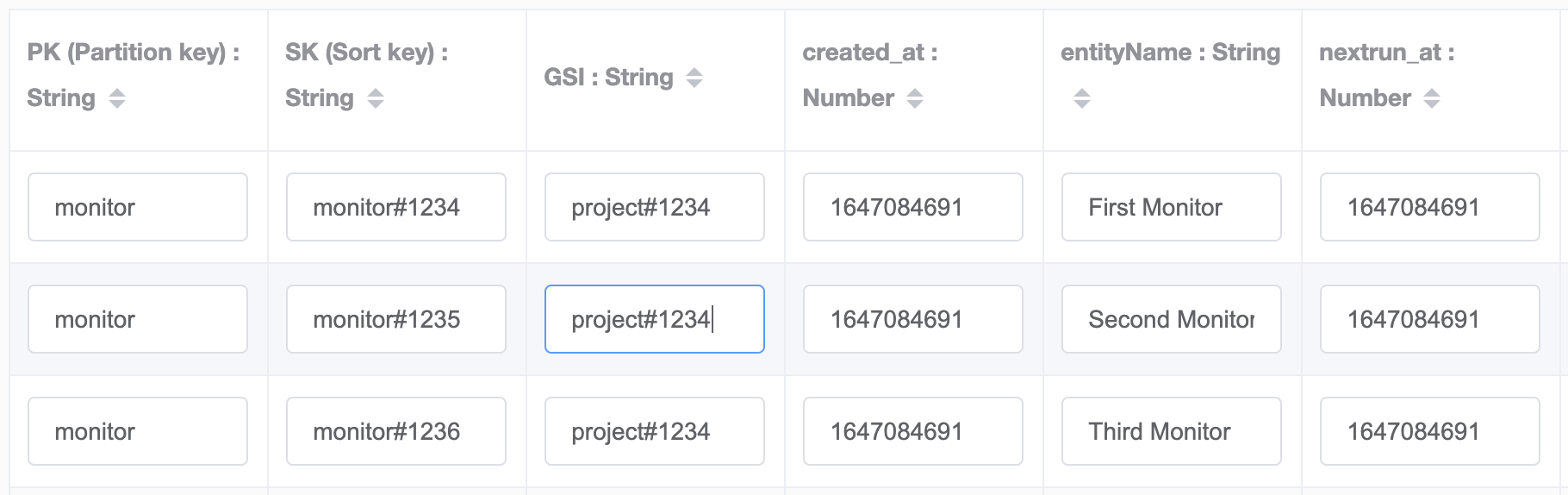
Then, when we query on the GSI index the key conditions will be GSI=project#1234 AND SK begins_with(monitor#) which will return the information we're looking for.
The query code would look like this:
const monitors = await ddb
.query({
TableName: process.env.DDB_TABLE,
IndexName: "GSI",
KeyConditionExpression: "#GSI = :gsi AND begins_with(#SK, :prefix)",
ExpressionAttributeNames: {
"#GSI": "GSI",
"#SK": "SK"
},
ExpressionAttributeValues: AWS.DynamoDB.Converter.marshall({
":gsi": "project#1234",
":prefix": "monitor#"
}),
});
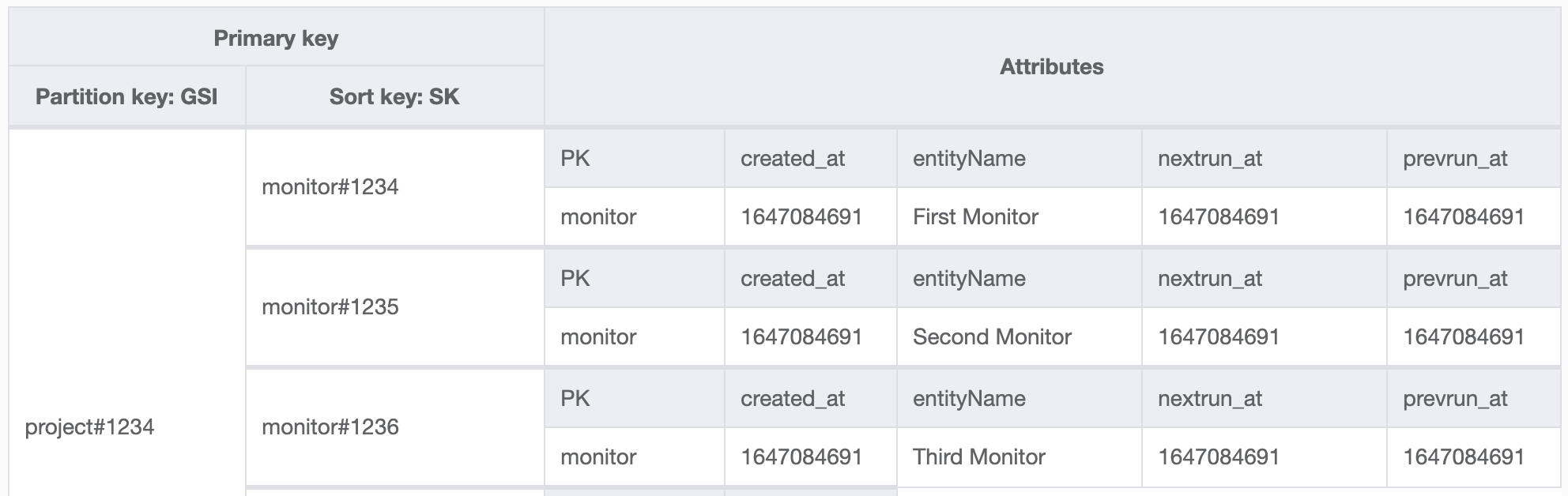
And here's yet another example of a one-to-many relationship. We need to show a list of all projects within the organization dashboard UI. In this case, we'll fill the organization ID in the GSI of the project item.
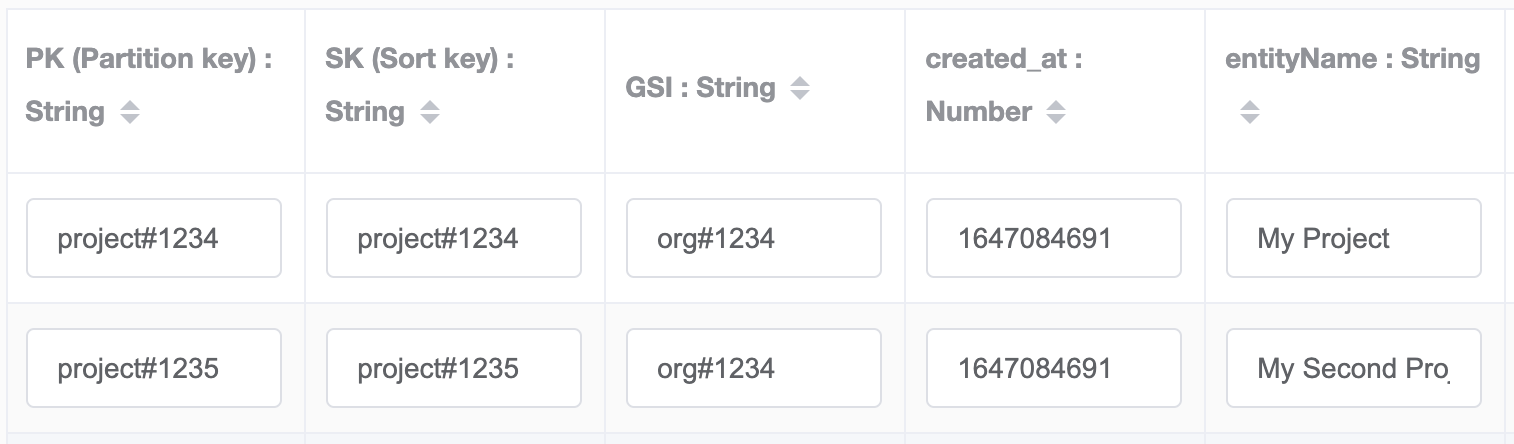
Querying the GSI with the key conditions GSI=org#1234 AND SK begins_with(project#) will return all the projects of that organization.

Many-to-Many relationship
The many-to-many relationships may seem a bit difficult at first, in a relational database we sort it out with a relationship table and two JOIN statements, but in DynamoDB this is not possible.
On Monithor, the core many-to-many relationship is between projects & users. We want to have granular access control for every project, so a user can have different access levels on multiple projects. A project can have multiple users.
We rely on the table sort key to store the association between entities, we store a concatenated value of user ID & project ID plus making use of GSI.
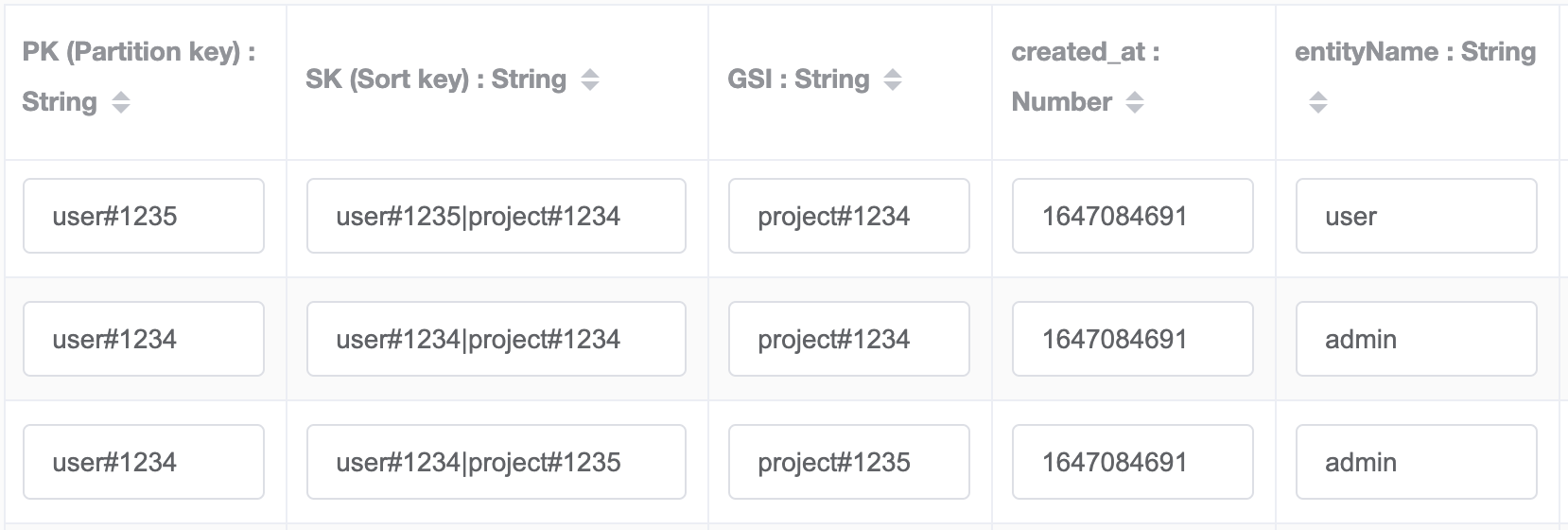
In the app UI, once the user logs in we'll want to display a list of the projects they have access to. We know the user ID from the login session so we'll have the query the table index with the following key conditions PK=user#1234 AND SK begins_with user#1234|project#
This will return all the project IDs the user#1234 has access to.
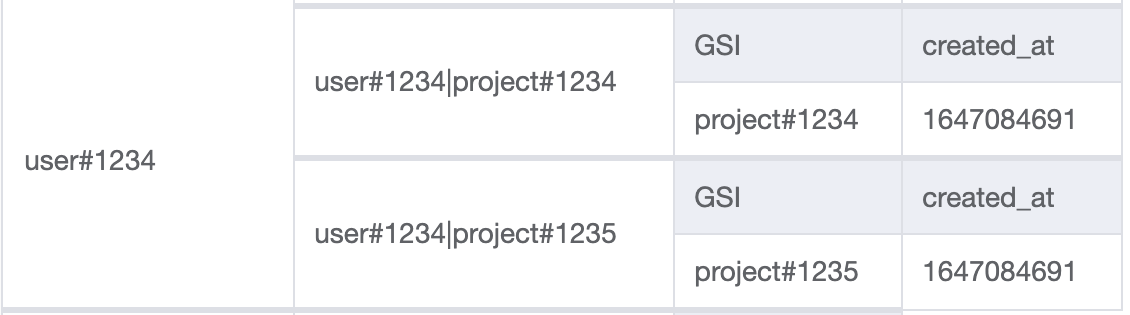
The code will look as follows.
const monitors = await ddb
.query({
TableName: process.env.DDB_TABLE,
KeyConditionExpression: "#PK = :pk AND begins_with(#SK, :prefix)",
ExpressionAttributeNames: {
"#PK": "PK",
"#SK": "SK"
},
ExpressionAttributeValues: AWS.DynamoDB.Converter.marshall({
":pk": "user#1234",
":prefix": "user#1234|project#"
}),
});
There's another UI screen where we need to display a list of users that have access to a project. This time we'll query the GSI* with the following key conditions GSI=project#1234 AND SK begins_with user#
This will return all the user IDs that have access to project#1234.
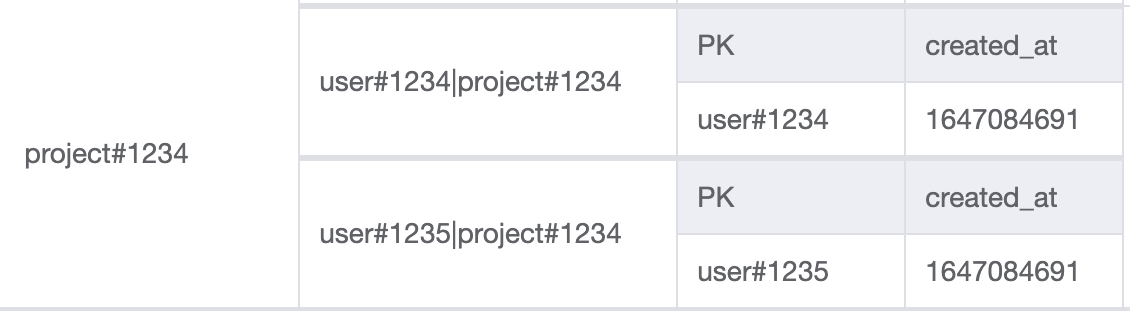
Resources
If you want to get deeper into DynamoDB I can't recommend enough Alex DeBrie's The DynamoDB Book.
Also, have a look at the Best Practices for Designing and Architecting with DynamoDB.
About
Monithor is a web service monitoring tool that helps you check websites or APIs' uptime and functionality and be alerted when they don't work as expected. It's built on AWS using the Serverless framework and it's open-source.