Running cronjobs at scale in AWS
With Serverless, DynamoDB, SQS, and Lambda functions.

An architect by trade, practicing architecture in the Cloud. 7x AWS Certified, AWS Community Builder, Serverless advocate, Vue enthusiast.
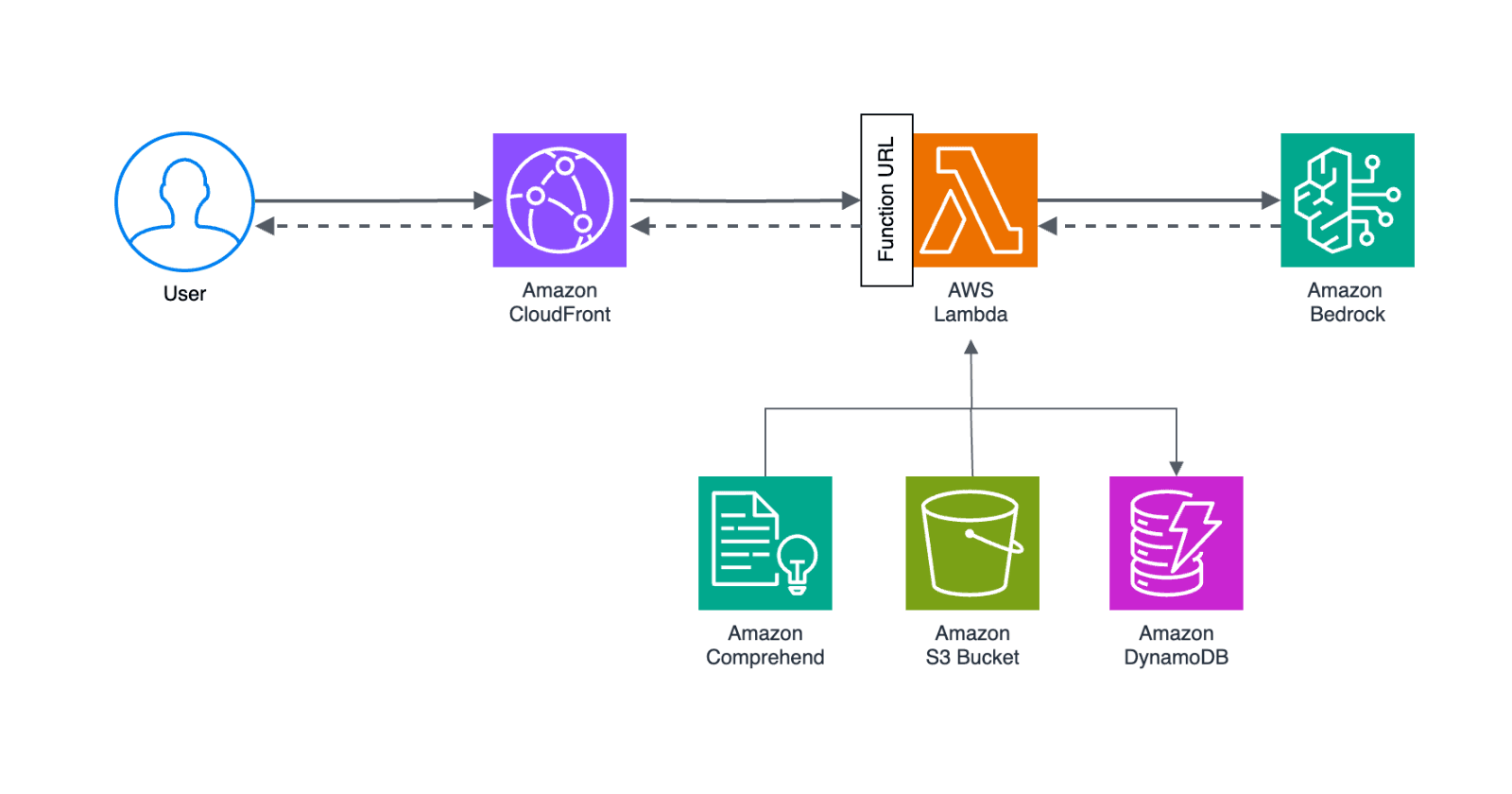
Monithor's core functionality is running jobs on a schedule. The service is built using the Serverless framework on top of AWS and allows users to schedule and run multiple monitoring jobs as frequently as once per minute.
There are various ways to run cronjobs on a schedule in AWS, I analyzed the options that follow the serverless principles. Although all of them can perform pretty well in the case of a single-tenant system, we'll offer a cloud-hosted plan, which is a multi-tenant system that needs to scale.
Solution requirements:
- precision - run as close to the scheduled time, preferably within seconds, an occasional execution delay up to a couple of seconds is acceptable
- scale - possibly tens of thousands of scheduled monitoring jobs, occasionally thousands to be executed around the same time
- costs - keep the AWS bill within reasonable limits
Now, let's dig into the options that AWS offers out of the box:
1. DynamoDB TTL + Streams
Set a Lambda function to process the DynamoDB Streams and react to data modifications. Each monitor job would have a DynamoDB entry with the expiration time (TTL) equal to the scheduled execution time. Once the entry is deleted would trigger the monitor runner logic.
Problem: The lack of precision.
As per DynamoDB docs TTL typically deletes expired items within 48 hours of expiration. - this means a task could be triggered minutes if not hours after the scheduled time.
2. EventBridge Rules (CloudWatch Events)
Create an EventBridge Rule for every monitor and set the Lambda containing the runner logic as the rule target.
Problem: The service quotas.
At the time of writing EventBridge Rules are limited to 300 per event bus and a maximum of 100 event buses per account. These are soft limits that will suffice for plenty of use cases, and can probably be increased on request. But the low initial limit is deterring.
3. Step Functions
We could make use of the wait state of the Step Functions and pause the workflow until the monitor's scheduled time of execution, it can be delayed even up to an entire year.
Problem: Relatively high cost.
The solution
Given that none of the out-of-the-box solutions tick all the requirements we have to start playing with the building blocks that AWS has to offer.
DynamoDB already stores all our scheduled tasks, including the time when they should run, so we'll create two Lambda functions: a Scheduler and a Runner (or executor). The Scheduler will pull the jobs to be executed in the next interval from DynamoDB and publish them into a SQS queue that will be immediately consumed by Runners.
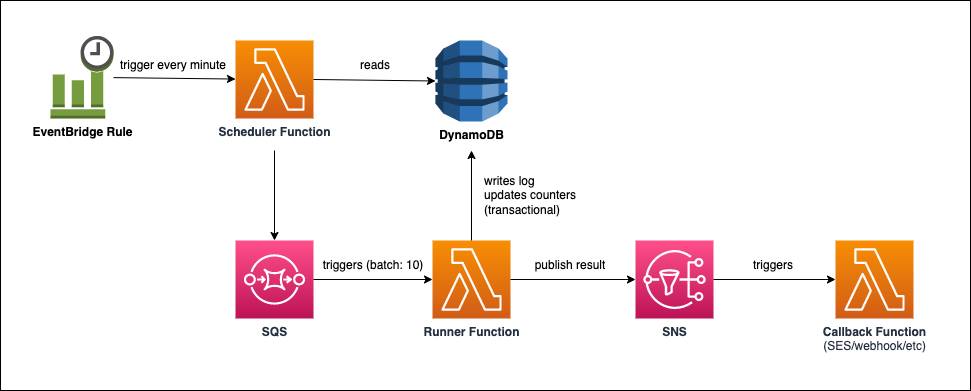
The Scheduler Function
The Scheduler function will be triggered by an EventBridge Rule once a minute.
The scope of the Scheduler function is to Query all scheduled monitoring jobs in the system (possibly thousands) and select those that are due for execution in the subsequent whole-minute interval. For example, the scheduler function that runs at 6:58 am will get all the monitors that need to run between 6:59:00 and 6:59:59 am. It would then enqueue those monitors into the SQS queue.
SQS allows us to set DelaySeconds parameter that will keep the message published to the queue invisible to consumers until the scheduled execution time.
The message payload contains all the info necessary for the Runner to execute the monitoring job, e.g. monitor config, project variables, and notification settings.
A drawback of this approach is that a monitoring job once sent to the queue to be executed can't be canceled but given the short time interval that's acceptable.
Scaling the Scheduler
The Scheduler function could become a bottleneck in case thousands of jobs have to be executed at the same time. There are intervals of the day that are prone to become hotspots, think the first minute of a day, or the first minute of every hour.
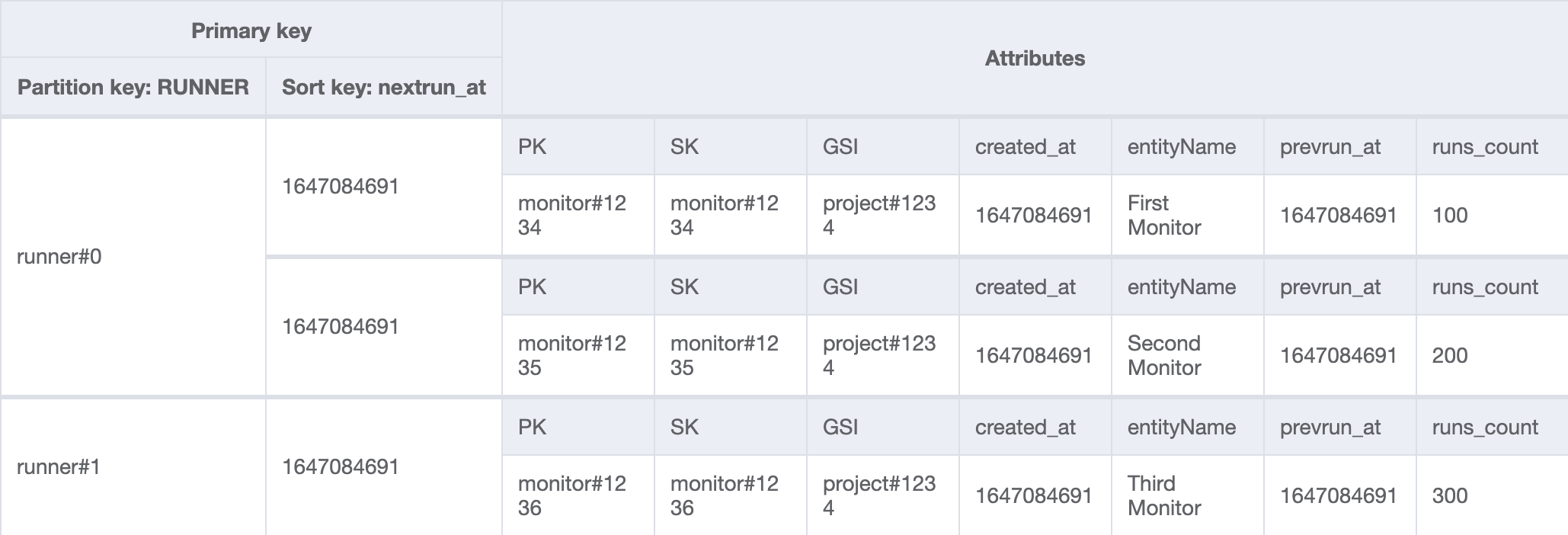
We added a dedicated global secondary index (RUNNER) that will help to Query which items are to be sent to the SQS queue. It uses the write sharding technique to better distribute writes across a partition key space and a scatter-gather query.
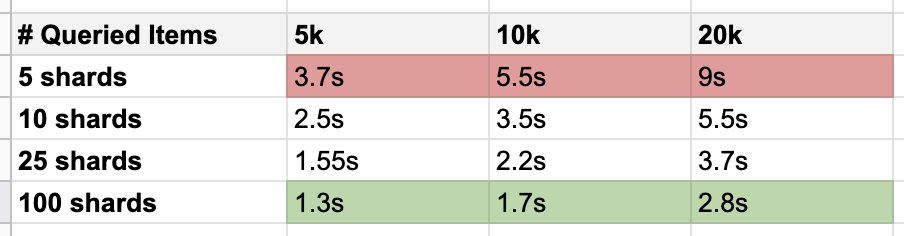
The tests show that it has a big impact on the DynamoDB query performance, so we can safely assume that we can get and send thousands, if not tens of thousands of monitoring jobs to the SQS queue in a matter of seconds.
If you want to dig deeper into Monithor's data model, I wrote an extensive post on the matter.
Here's how the Scheduler function code looks and how scatter-gather queries are done:
// get the monitors of this cron interval
const promises = [],
sqsMessages = [],
sqsPromises = [],
// create shards array starting 0
shards = [...Array(process.env.SHARDS_COUNT).keys()];
// loop shards - scatter-gather query
for (var idx in shards) {
promises.push(
ddb
.query({
TableName: process.env.DDB_TABLE,
IndexName: "RUNNER",
KeyConditionExpression:
"#RUNNER = :runner AND #SK BETWEEN :t1 AND :t2",
FilterExpression: "#status = :status",
ExpressionAttributeNames: {
"#RUNNER": "RUNNER",
"#SK": "nextrun_at",
"#status": "status",
},
ExpressionAttributeValues: AWS.DynamoDB.Converter.marshall({
":runner": "runner#" + idx,
":status": "ENABLED", // only the enabled monitors
":t1": t1, // next rounded minute start
":t2": t1 + 59,
}),
ScanIndexForward: false,
})
.promise()
);
}
// await all promises to finish // parallel
await Promise.allSettled(promises)
.then((res) => {
res.forEach((v) => {
if (v.value.Items) {
v.value.Items.forEach((item) => {
// unmarshal item
item = AWS.DynamoDB.Converter.unmarshall(item);
// create SQS mesage
sqsMessages.push({
Id: item.PK.replace("monitor#", ""),
MessageBody: JSON.stringify(item),
// delay the diff in seconds until scheduled time
DelaySeconds:
item.nextrun_at -
Math.floor(+new Date() / 1000),
});
});
}
});
})
.catch((err) => {
console.log(err.message);
return [];
});
// no monitors to enqueue, stop
if (!sqsMessages.length) {
return [];
}
// group sqs messages into chunks of 10 for batch sending
chunkArray(sqsMessages, 10).forEach((chunk) => {
sqsPromises.push(
sqs
.sendMessageBatch({
Entries: chunk,
QueueUrl: process.env.QUEUE,
})
.promise()
);
});
// wait for the sqs messages to be published
await Promise.allSettled(sqsPromises)
.then()
.catch((err) => {
console.log(err);
});
The Runner function
The Runner function will be triggered by the SQS queue, will receive up to 10 monitoring jobs and execute those in parallel. The execution of a runner consists in making the monitoring request and asserting the results and writing in the DynamoDB table a log entry and updating the monitor's next execution time and counters.
Depending on the notification settings, the assertion result is further published to an SNS topic that triggers a Lambda fan-out function that handles the notification sending (email, webhooks, etc).
Scaling the Runner
When monitoring jobs are available in the queue, Lambda reads up to 5 batches and sends them to our Runner function. If jobs are still available, Lambda increases the number of processes that are reading batches by up to 60 more instances per minute.
This will allow us to run thousands of monitoring jobs per minute.
Resources
- Yan Cui's post on Using CloudWatch and Lambda to implement ad-hoc scheduling
- Michael Bahr's post on Serverless Scheduler
About
Monithor is a web service monitoring tool that helps you check websites or APIs' uptime and functionality and be alerted when they don't work as expected. It's built on AWS using the Serverless framework and it's open-source.