Streaming AI Responses on AWS Lambda
A clean serverless pattern for streaming real-time AI workflow responses with Server-Sent Events and AWS Lambda
An architect by trade, practicing architecture in the Cloud. 7x AWS Certified, AWS Community Builder, Serverless advocate, Vue enthusiast.
While building Creditaki, an AI-powered credit assistant, I had two non-negotiable requirements: a fully serverless architecture and real-time streaming for the best user experience.
Users expect AI responses to appear token by token, like ChatGPT. But AWS Lambda and API Gateway aren't designed for long-lived, streaming responses out of the box.
I wanted Server-Sent Events (SSE): a simple way to stream AI responses into a chat UI without managing servers. Here's how Lambda Response Streaming solved both problems.
The Problem
Staying serverless while delivering real-time UX meant every common approach had deal-breaking limitations:
API Gateway HTTP + AWS Lambda (proxy)
30-second timeout limit for HTTP APIs
No true streaming, responses buffer until function completion
API Gateway WebSockets
- Requires complex connection management and keepalive logic
Async job + polling
- Poor UX, users stare at loading spinners while clients poll for updates
What I wanted was progressive delivery: send partial LLM streaming responses immediately, without breaking my serverless constraint
The Solution: Lambda Response Streaming
AWS introduced Lambda Response Streaming about two years ago (2023), but the ideal use cases weren't immediately obvious.
Interacting with AI models turned out to be the perfect fit.
Lambda Response Streaming lets functions send data directly to clients instead of buffering everything until completion. Combined with the rise of streaming LLM models like those in AWS Bedrock, this creates exactly what users expect from modern conversational AI interfaces.
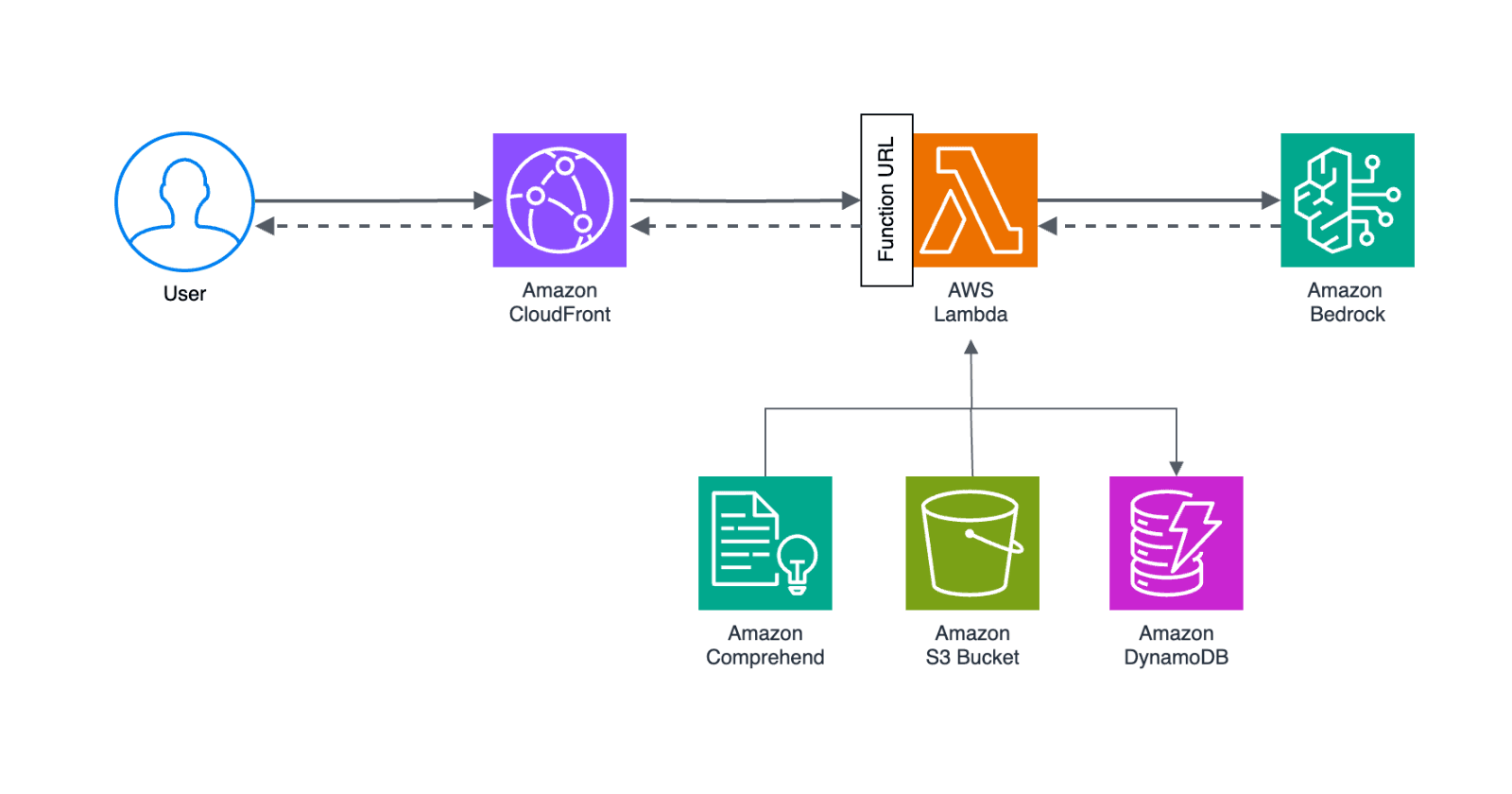
My architecture handles privacy compliance while leveraging the best AI models:

The flow is straightforward but powerful:
User request flows through CloudFront to the Lambda Function URL
Comprehend extracts and anonymizes personal financial data
System prompt is read from S3 bucket (if not cached)
User message is stored in DynamoDB
Anonymized data sent to Bedrock for AI analysis
Bedrock streams tokens back through Lambda as Server-Sent Events
User gets real-time responses without personal data leaving the EU
Why CloudFront? It provides out-of-the-box country-level access control. Since Creditaki targets a single market, I wanted to prevent non-targeted users from consuming expensive AI tokens.
The timing worked perfectly: Lambda Response Streaming matured just as AI model streaming became the expected UX standard.
Implementation with Node.js and TypeScript
Infrastructure as Code
I’m using AWS CDK to create the Lambda function and Lambda Function URL resources.
The Lambda Function URL requires specific configuration for response streaming:invokeMode: RESPONSE_STREAM enables the streaming capability. By default, Lambda will buffer the entire response.
const chatFunction = new nodeLambda.NodejsFunction(this, "ChatFunction", {
runtime: lambda.Runtime.NODEJS_20_X,
timeout: cdk.Duration.seconds(180), // Extended timeout for AI processing
memorySize: 256,
environment: {
DDB_TABLE: this.ddbTable.tableName,
S3_BUCKET: this.s3Bucket.bucketName,
// other env
},
});
const chatFunctionUrl = chatFunction.addFunctionUrl({
authType: lambda.FunctionUrlAuthType.NONE,
invokeMode: lambda.InvokeMode.RESPONSE_STREAM, // this is the setting
cors: {
allowedOrigins: ["*"],
allowedMethods: [lambda.HttpMethod.GET, lambda.HttpMethod.POST],
},
});
The 180-second timeout accommodates AI workflows where models use external tools. Bedrock models can call APIs, search knowledge bases, or perform multi-step reasoning that takes time to complete.
Application Code
The core of Lambda Response Streaming is the streamifyResponse wrapper and custom stream processing.
// Lambda handler
exports.handler = awslambda.streamifyResponse(
async (event, responseStream) => {
await pipeline(
Readable.from(sendMessage(event)),
responseStream
);
}
);
Since I wanted to use POST requests for chat messages, I used fetch with manual stream processing instead of EventSource (which only supports GET).
// frontend integration
async function sendChatMessage(message) {
const response = await fetch('/c', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message })
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
const lines = chunk.split('\n');
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.slice(6));
if (data.type === 'token') {
appendToChat(data.content); // Update UI in real-time
}
}
}
}
}
This gives users the immediate feedback they expect from AI interactions - tokens appear as they're generated, just like ChatGPT.
Why Manual Stream Processing Instead of EventSource?
The browser's EventSource API is the standard way to consume Server-Sent Events, but it has a critical limitation: it only supports GET requests.
In my chat implementation, I need both methods:
POST /c - Send new messages with user input
GET /c - Retrieve chat session history
// This won't work for sending messages - EventSource only supports GET
const eventSource = new EventSource('/c', {
method: 'POST', // ❌ Not supported
body: JSON.stringify({ message: "Hello" })
});
// Solution: Use fetch for both GET and POST with consistent stream processing
const response = await fetch('/c', {
method: 'POST', // ✅ Send messages
body: JSON.stringify({ message: "Hello" })
});
// Same streaming logic works for GET requests too
const sessionResponse = await fetch('/c', {
method: 'GET' // ✅ Get chat history
});
Using fetch for both endpoints keeps the streaming implementation consistent across your API, rather than mixing EventSource (GET only) with custom fetch logic (POST).
Many developers miss this nuance when building chat interfaces - they assume EventSource will handle all SSE scenarios.
Key Takeaways
Lambda Response Streaming transformed how I deliver AI experiences at Creditaki:
Real-time LLM streaming without complex infrastructure
AWS Bedrock integration with privacy compliance
Cost control through CloudFront geo-blocking
Simple Node.js implementation compared to WebSocket alternatives
In short: ChatGPT-style streaming, on a 100% serverless stack.
The pattern works well for any AI application where users expect streaming responses. As more developers build AI workflows, Lambda Response Streaming provides a clean serverless solution that scales automatically.
Check out Creditaki - Credit AI Assistant to see this streaming pattern in action.



